

先进端侧 AI 解决方案
作为开发高效能、高能效片上系统产品的供应商,MediaTek 将强大的集成 AI 处理器带入多样化的产品生态系统中。
现在,MediaTek 每年芯片出货量超过 20 亿颗,其中许多都包含了 AI 处理器,这使我们成为世界前列的 AI 供应商之一。凭借广泛的市场覆盖范围,您将在家用设备、教育、企业、移动设备和车辆中使用到我们的人工智能技术。
MediaTek 混合 AI——端侧和云侧
MediaTek 在推动和支持生成式 AI 应用和技术的采用方面具有独特优势,无论是在云侧部署、设备的端侧处理,还是结合云侧与端侧优势的混合方案,均能提供卓越支持。

完整的 MediaTek AI 生态系统。
MediaTek AI 生态系统涵盖硬件、开发工具以及软件开发工具包(SDK)。
软件开发者可综合使用多种工具和算法,与此同时,MediaTek NeuroPilot 支持“一次编写,随处应用”,简化基于 MediaTek 全系列产品的应用程序开发过程。

以 5 种常见的神经网络作为基准测试,根据能效曲线,MediaTek 深度学习加速器(DLA)的能效相较于典型 CPU 高 27 倍,相较于典型 GPU 高 15 倍。
.png)
MediaTek NPU 技术
联发科 NPU 是一个高度可扩展的多核处理器,根据应用需求,可能包含不同数量的 MDLA 和 MVPU 核心。
2023年,MediaTek 推出第 7 代 NPU,专为基于 Transformer 模型的生成式 AI 加速而设计。第 7 代 NPU 采用高度灵活的设计,可根据应用需求调整计算单元、功耗、内存带宽和内存容量,无论是在智能手机 SoC 中还是作为数据中心级芯片的一部分,均能提供卓越性能。
- 基于硬件的多核调度器。
- 专用 DMA 引擎,可执行深度层融合和数据压缩,降低对 DRAM 带宽的需求。
- 能效智能优化和共享内存感知。
- MediaTek 设计的片上网络(NoC),可实现低延迟的核间通信。
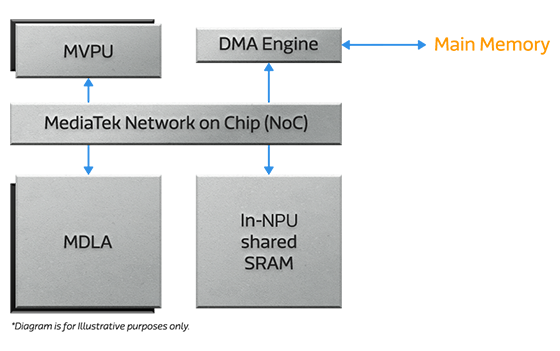
- 具备高性能、可编程、多功能特性,并采用高能效的 MAC 架构,可在广泛的神经网络应用中实现数据重用。
- MDLA 专为处理不同类型的网络而设计,包括:
- (a) 卷积神经网络
- (a) 卷积神经网络
- (c) 长短期记忆模型
- (d) 基于 Transformer 的移动双向编码器表示(BERT)
支持 INT4/INT8/INT16、FP16、BF16
- 和混合精度计算,以进一步降低功耗。
- 与 ISP 和 DPU 之间的子系统通信可大幅减少延迟和功耗。

- 针对计算机视觉(CV)和神经网络(NN)应用优化的通用 DSP。
- 在摄影、摄像和视频流播放等视觉处理应用中,实现卓越能效。
