

先進端側 AI 解決方案
作為開發高性能且高能效系統單晶片產品的行業領導者,MediaTek 已經將其強大的自研 AI 處理器的優勢引入到多樣化的產品生態系統中。
我們每年向連接設備出貨超過 20 億顆晶片,其中許多都內建 AI 處理器,使我們成為全球領先的 AI 供應商之一。憑藉我們廣泛的市場覆蓋,您可以在家中、教育、商業、移動設備和車輛中找到我們的 AI 技術。
聯發科技混合 AI — 端側和雲端
聯發科技在推動和支援生成式 AI 應用和技術的採用方面具有獨特優勢,無論是在雲端部署、設備的端側處理,還是結合雲端與端側優勢的混合方案,均能提供卓越支援。

完整的聯發科技 AI 生態系統
聯發科技 AI 生態系統涵蓋硬體、開發工具以及軟體開發工具包(SDK)。
軟體開發者可綜合使用多種工具和演算法,同時,MediaTek NeuroPilot 支援“一次編寫,隨處應用”,簡化基於聯發科技全系列產品的應用程式開發流程。

以 5 種常見的神經網路作為基準測試,根據能源效率曲線,聯發科技深度學習加速器(DLA)的能源效率相較於典型 CPU 高 27 倍,相較於典型 GPU 高 15 倍。

MediaTek NPU 技術
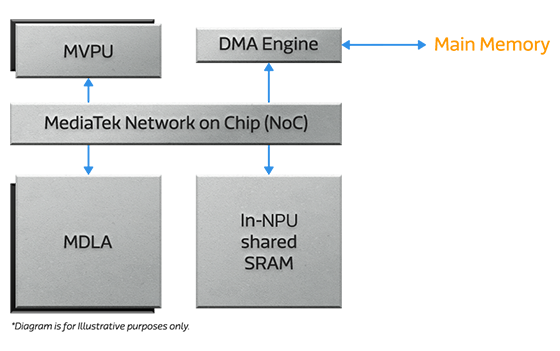
MediaTek 的 NPU 是一款高度可擴展的多核心處理器,可以根據應用需求包含不同數量的 MDLA 和 MVPU 核心。
2023年,聯發科技推出第 7 代 NPU,專為基於 Transformer 模型的生成式 AI 加速而設計。第 7 代 NPU 採用高度靈活的設計,可根據應用需求調整運算單元、功耗、記憶體頻寬和記憶體容量,無論是在智慧型手機 SoC 中還是作為資料中心級晶片的一部分,均能提供卓越效能。
- 基於硬體的多核心調度器。
- 專用 DMA 引擎,可執行深度層融合和資料壓縮,降低對 DRAM 頻寬的需求。
- 能效智慧優化和共享記憶體感知。
- 聯發科技設計的片上網路(NoC),可實現低延遲的核間通訊。
- 具備高效能、可程式化、多功能特性,並採用高能源效率的 MAC 架構,可在廣泛的神經網路應用中實現資料重複使用。
- MDLA 專為處理不同類型的網路而設計,包括:
- 卷積神經網絡
- 循環神經網絡
- 長短期記憶模型
- 基於 Transformer 的行動雙向編碼器表示(BERT)
- 支援 INT4/INT8/INT16、FP16、BF16 和混合精度計算,以進一步降低功耗。
- 與 ISP 和 DPU 之間的子系統通訊可大幅減少延遲和功耗。

- 針對電腦視覺(CV)和神經網路(NN)應用最佳化的通用 DSP。
- 在攝影、攝影和視訊串流等視覺處理應用中,實現卓越能效。
